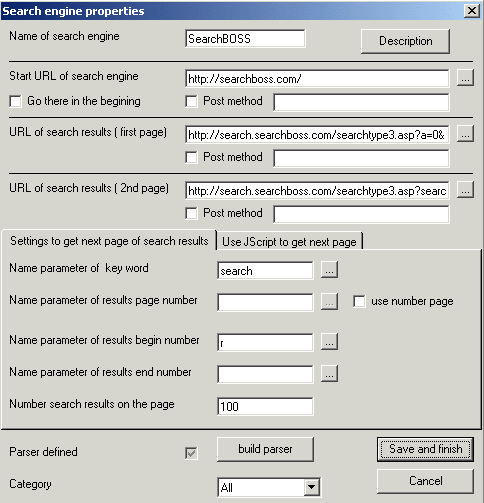
Click button 'Engines' , the 'Selection dialog' will appear.
Step 2
Click 'Define engine' button on properties tab. 'Search engine properties' dialog will appear.
Step 3
Fill up appropriate fields using 'Search engine properties' dialog .
Fast Email Extractor
Overview
Fast Email Extractor is a simple, fast and reliable way to get email
addresses from the web . Specify key words of your search and the tool brings
you hundreds of addresses from web sites found by the search
engine. The tool supports all major search engines but has
UNIQUE ABILITY TO ADD ANY SEARCH ENGINE OR WEB SITE THAT HAS A SEARCH
FACILITY. You can define your search by yourself
and as many engines as You want! Another great feature of the tool is an
option to search into domains, like .com , .net , .ca or any
other.
How
to search
How to define
new search engine
How to save
results
The following examples describe typical tasks for the product and corresponding user actions.
Example 1 Task description: I need to find email addresses for
Canadian real estate agencies.
Actions: I specify “Russia real estate
agency” and press the “Search” button.
Example 2. Task Description: I have a list of URLs in the Access database and I need to extract the email addresses from them. Actions: I export the URLs as a text file without the text qualifier (none). Using the “Load” button on 'extract from web site' tab, I load the saved URLs.
Example 3. Task Description: I need to extract email addresses from “www.lencom.com'“. Actions: I specify “www.lencom.com” on 'extract from web site' tab and press the 'Add to the list' and the “Start” button.
Example 4: Task Description: The Extractor returns unrelated
email addresses. I need to narrow the search. How do I do it?
Actions: I go
to a selected search engine (e.g. www.google.com) and start experimenting with
key words to narrow my search results. I then specify the same key words for the
Extractor.
Example 5: Task Description: I have a directory with 1300 text files in it and I need to extract all email addresses that contain 'aol' . Actions: I go to the ”Get email from files” tab, select my directory and specify a "*.txt" mask, check “Only emails that contain”, specify my filter (”aol”) and press the “Search” button.
Example 5: Task Description: I need extract emails from .net only. Actions: I go to 'Extract from domains' tab , specify my search word and press button 'Start'
How to define new search Engine
Step 1.
Click button 'Engines' , the 'Selection dialog'
will appear.
Step 2
Click 'Define engine' button on properties tab. 'Search engine
properties' dialog will appear.
Step 3
Fill up appropriate fields using 'Search engine properties' dialog
.
| FIELD | DESCRIPTION |
| Name of search engine | Any search engine that You define suppose to have short and understandable name. Because this name will be used as a key to find the engine , it's strongly recommended not to use spaces or special characters. For example 'MyEngine' is a good name but 'My Engine' or 'My-Engine' are not. |
| Start URL |
The start URL is used for opening working
session with target web site ,if required, before doing any search. The
good example of such need is login action. For example if You have
username and password for employment web site , You should login ,provide
that URL for this field and mark 'Go there in the beginning's checkbox. If
You don't need open the session , anyway it's good idea to provide some
URL that leads to main page. For example for 'SearchBoss' should
be defined 'http://www.SearchBoss.com' Please use button ... to navigate there and select it without any typing. |
| URL of search results (first page) | The URL address of the first page of search
results can be different from the second and other pages. Please use
button ... to navigate there. Please use button ... to navigate there and select it without typing. |
| URL of second page | Please use button ... to navigate there and select it without typing. |
| Define next page | How navigate to the next page of the search results? For most engines it's rather simple but for some You'll need use JScript (look picture below). |
| Name parameter of key word |
http://search.searchboss.com/searchtype3.asp?search=car&p=0&pact=0&s=10&r=10&a=0
The URL above brings search results from 'SearchBOSS' using 'car'
as the search word. Which variable in that URL is equal to 'car'? Of course 'search'
. |
| Name parameter of page number | http://search.microsoft.com/us/dev/default.asp?qu=webbrowser&ig=06&p=2 http://www.onesearch.com/cb/os.cgi?q=car&id=&s=11&p=2&a=10What's the structural difference between 2 URLS above? First URL uses page numbers to list results (parameter p) while second one uses number of result to start from , to display second result page. If your search engine uses pages You should specify parameter name and mark 'use number page' checkbox. |
| Name parameter of begin number | http://search.microsoft.com/us/dev/default.asp?qu=webbrowser&ig=06&p=2 http://search.searchboss.com/searchtype3.asp?search=car&p=0&pact=0&s=10&r=10&a=0 What's the structural difference between 2 URLS above? First URL uses page numbers to list results (parameter p) while second one uses number of result to start from , to display second result page. If your search engine uses number of result to start from , You should specify name of the parameter. (in our example it's 'start' for second URL) |
| Name parameter of end number | http://search.aol.com/dirsearch.adp?query=car&first=11&last=25 Please take a look how well known provider defines its second page of search results. It declares not only number result to start from but number result to finish the display. If your engine has it please provide it here. |
| Number results per page | Any page of search results has a number results on the page. Just count them and enter the number here. |
| Parser definition | To have a data instead of HTML page You need a parser. The description of how to define the parser is below this table. |
| Category | It's easier to browse engines when they're categorised. If the category does not exist yet please select 'All' . You can define category and edit the engine later. |
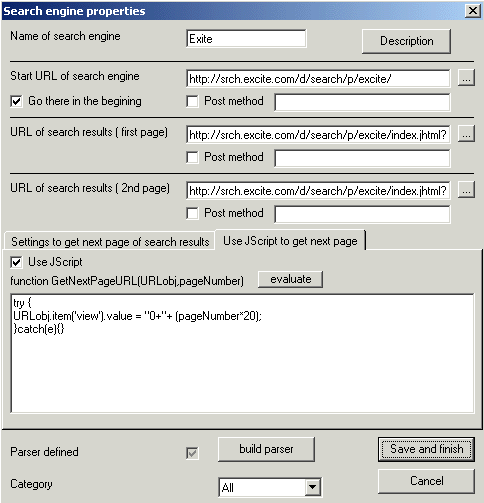
Some search engines use quit complex methods to define
next page.In that case You can define your own JScript function that receives
object URLobj and number of the next page as parameters and uses some algorithm
to define URL of the
nextpage. Letstakealookat srch.excite.com/d/search/p/excite/index.jhtml?Keywords=car&view=0%2020&prev=0%200%200&c=web
We know that next page variable is 'view' and it's supposed to be like
view=0+20 where 20 is number results to start with. But it looks weird
like 0%2020 , because it's URL encoded. All what You need to know about
URLobj is that it has all url variable parsed in collection and You can access
it using following syntax URLobj.item('nameofmyvariable').value
Any time when
the software wants to go to the next page it will call that function providing
You parameters pageNumer (1,2,3,...) and URLobj. Your job is to define
appropriate code to set URLobj.item('nameofmyvariable').value to new value.
Please pay attention that 'nameofmyvariable' is just an example and in your case
the name will be different.
PARSER Creation
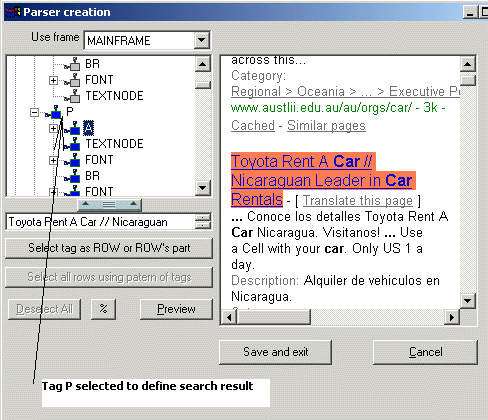
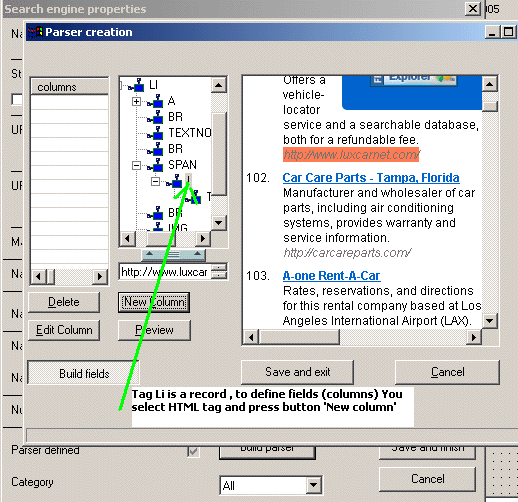
Sometimes search results have a complicated structure . Just to have text or URL is not enough. The columns (or fields) are designed to parse the records itself extracting required parts from the search result.
How to save
results
Press button 'Save as' , the save dialog will appear.
It asks You for file name , please use 'Browse' button.
If You're not marking
the 'Save URLs' checkbox and not specifying text qualifier the results in target
file will appear as
firstemail@lencom.com
secondmail@lencom.com
If You mark the 'Save URLs' checkbox and specify text qualifier as " and separator as , the results will appear as
"firstemail@lencom.com","http://www.lencom.com/index.htm"
"secondmail@lencom.com","http://www.lencom.com/parsing.htm"